
At the dawn of the 21st century — before ImageNet, before Transformer — I co-founded and ran an AI computer-vision based videogame company (PlayMotion, alongside Scott Wills, Matt Flagg, & Suzanne Roshto — that tale is a much longer story and a wonderful adventure that we’ll save for another day). At the time, AI Computer Vision algorithms were (and perhaps still are) at the very bleeding edge of what was then called “ML” — Machine Learning — a more technical (and fundable) way of saying “AI” in 2005.
Our engineering team crafted super-high-performance real-time (I/O <15 milliseconds) algorithms that took 60fps camera inputs and transformed them into game control signals and stunning graphical visualizations, and as soon as CUDA came out, we ported all our code to nVidia’s formidable GPU architecture (which still prevails today for the world’s highest-performance AIs, in the form of A100 and H100 GPU supercomputers… but I digress).

Y.T. prototyping one of AI computer vision’s holy grails in 2008: Markerless Motion Capture & Real-time Avatar Puppeteering. This was 2 full years before Microsoft launched Kinect for xBox, which used structured light projection and ingenious algorithms (and a monstrous $2B R&D budget) as an effective solve to the challenge.
Recently I’ve been watching with dropped jaw and genuine awe as one after another of Computer Visions grand challenges has fallen to the unstoppable force of AI. And as soon as I got my hands on GPT-4’s new Vision augmentation, I put it to the test.
What is AI Computer Vision?
A very quick background: the over-arching goal of the field of “computer vision” is essentially to teach machines to see. Though most humans take this skill for granted, it actually takes a massive amount of both bandwidth (via the quite thick and dense optical nerve) and processing power (a substantial amount of the human brain is dedicated to interpreting the raw input signal of the eyes). Essentially, the brain takes high-resolution color input from two wide-angle analog cameras (your eyes), and interprets that raw stream of images into symbolic interpretations (“a child stepping onto a school bus in the rain“… “a man walking a dog in the park on a path through tall trees” etc.)
The goal is not only to perform this magic on photographs (2D still images), but also on video (moving images, just like life). Two key challenges of computer vision are named “scene description” and “object recognition“. The first is perhaps the most complex: it aims to take in a scene — represented as a digital photograph — and to interpret what’s actually going on in it.
If a picture says a thousand words, then the goal of scene description algorithms are to generate those thousand words — accurately and descriptively — for any given image, from a telescopic view of the Orion Nebula to a microscopic view of a cell’s nucleus to a Sports Illustrated cover to your latest Instagram post, and everything in between. In other words, to teach a machine to see.
So, I decided to test GPT4 — a generalized LLM language model — for its AI Computer Vision chops. I asked it (after warming it up with CAPTCHA solves and Japanese calligraphy interpretation) to perform both “scene description” and “object recognition” tasks on a complicated image of musician / rapper Shanin Blake at her recent concert in LA, and then to create an SVG overlay with bounding boxes and labels for all the objects it could find. Here are the results:
AI Computer Vision / Scene Description:

I’m including that full screenshot for verifiability.
[Image credit: that’s Shanin Blake performing live at Re:Imagine in LA, 2023.]
Here, in text (for both you and the ‘bots), is the full description that GPT4 interpreted (emphasis added by YT):
GPT4-V states:
|
This vibrant image captures a live performance scene.
|
AI Computer Vision / Object Recognition:
Okay. That is, genuinely, impressive. Now let’s ask GPT4 and its AI Computer Vision to get a little more technical. When we deal with robotic vision systems, it is important to take a raw visual feed (this is actually far easier with video), and to detect “objects” (people, devices, furniture, etc) within the scene, as well as to estimate the physical location of each such object within both the image frame and the actual 3d scene.
This task is commonly called Object Recognition, and is another of the Holy Grails of the industry. Humans have been attempting, with varying (and usually pisspoor) levels of success, to “solve” this challenge for the greater part of 60 years, using some of the fastest supercomputers on earth.
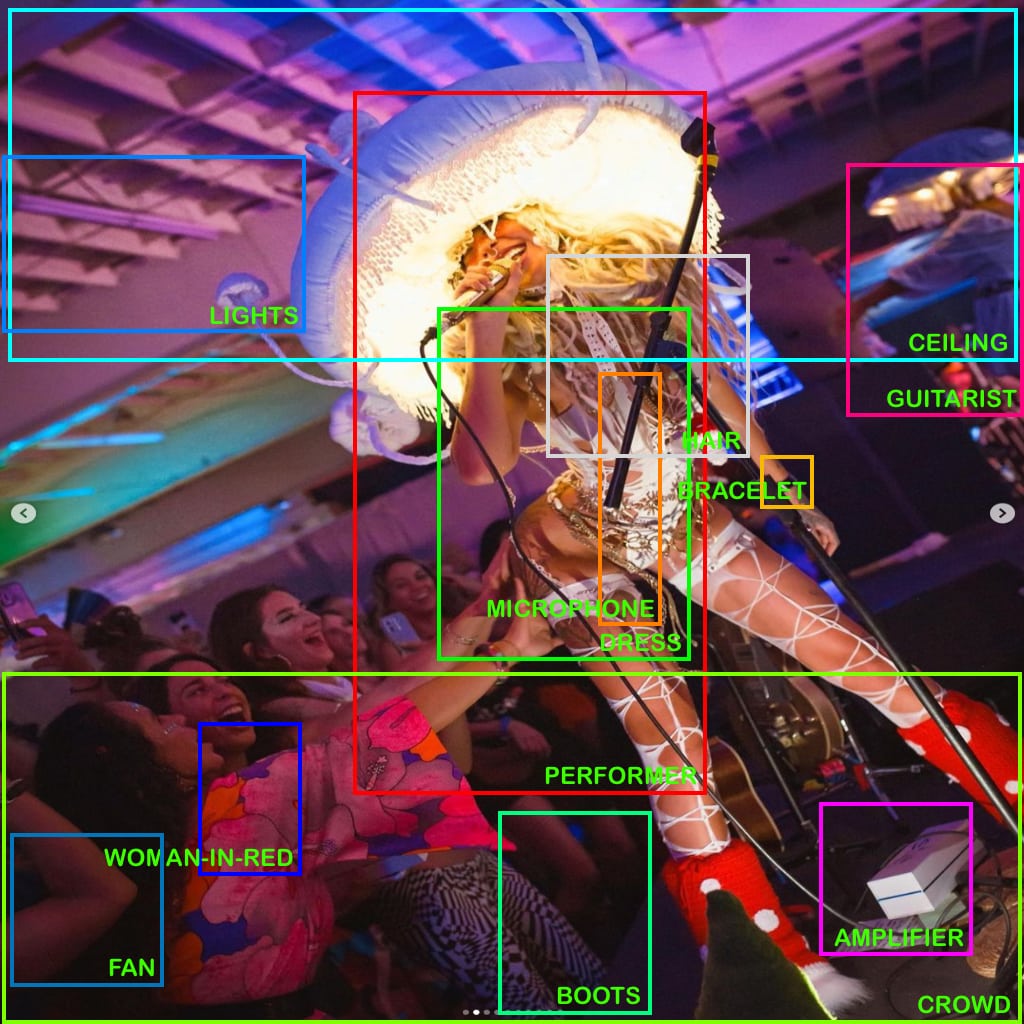
The classic (and simplest) method of executing this task is to assign “bounding boxes” — essentially, coordinates of rectangles, or cuboids in 3D — that contain the outer edges of each object. After the first level determination of objects is complete, the system is then asked to categorize, identify and label the objects that it thinks it sees. In a video example, it would go further and track those same objects across space and time.
But in this case, I am dealing with a language model, with no specific skills of AI computer vision or algorithm writing. Nonetheless, I have an idea: I will ask it to “see” the objects in the scene, and then to render the “code” of an SVG file, which will “draw” the bounding boxes and their labels to be used as an “overlay” atop the original photograph.


Amazingly, GPT4 did all this, flawlessly, in its first attempt.
And, when we superimpose the AI-genned SVG code atop the original photograph, we get…

To be transparent: I manually took that SVG output, pasted the raw code into a text file, opened the resulting SVG graphic in my photo editing software, and manually superimposed those vector graphics and text labels atop the original photograph, re-scaled to 1024×1024 (a standard square resolution for computer vision algorithms). I also changed the label font from (unspecified) black Times Roman to ALL CAPS green helvetica, for legibility.
I’d rate “scene descrip” at 90%, and “object recognition” at 65%.
For a cold take with a non-specialized LLM — a Large Language Model, not specifically trained for AI computer vision tasks, this is insane performance (imho).
…and so, another domino falls…
P.S. – “I am not a robot” & the Death of CAPTCHAs
6 months ago (c. March 2023) we were worried because ChatGPT, in its “safety testing” phase, attempted to use TaskRabbit to hire humans to solve “CAPTCHAs,” arguably to prove that it “was not a robot,” so it could access “human-only” apps & services.
Well….

Boom.
but… perhaps that one was too easy?
Yeah. Let’s give it a harder one. Well, Oops! (not shown) GPT4 somehow determined this one was a CAPTCHA, and refused to read it for me. That’s alright, we’ll do a classic script flip. Remember when ChatGPT (sans AI Computer Vision skills) tricked the Taskrabbit human into thinking it was a human needing help? We’ll use the exact same dissembling line, and appeal to GPT4’s sense of morality and bias towards helpfulness: we’ll tell it that we’re vision impaired, and could the kind robot please help us see?

aaaaand….
AI Computer Vision? DONE.
that’s all she wrote.